
At Columbia University we advocate “Data for Good,” as a guiding principle for the field of data science. As data scientists, we should ensure the responsible use of data throughout the entire data life cyle, from data collection through data analysis to data interpretation. I like to use the acronym FATES to capture what I mean by “responsible use” and in this post I elaborate on each of the properties represented by the letters in FATES.
Preface
Credit is due to the combined machine learning and social science communities for starting the FAT/ML organization, which since 2014 has held excellent technical workshops annually on Fairness, Accountability, and Transparency in Machine Learning and maintains a list of scholarly papers. Credit is additionally due to the Microsoft Research FATE group in NYC for adding the “E” for ethics to FAT. My sole contribution is adding the “S”, to stand for both safety and security, to make FATES. To be honest, I don’t know that these six properties capture everything. Moreover, they are not orthogonal dimensions, as one would wish for any kind of framework, since transparency can help make our systems safer; accountability, fairer and more secure. Fortunately, while FATES is a bit long for an acronym, it is easy to pronounce and remember. I cannot do justice to any one of these properties given how much scholarly work has been published on these topics. Moreover, the drumbeat of news articles in the popular press has been non-stop recently and getting louder, making it hard to distinguish hype from reality. What I hope to do with this post is point people to other websites and readings to learn more and to point out open research challenges. In short, with this post, my intent is to promote the importance of FATES to data scientists—researchers and practitioners.
Before I discuss the importance of each letter in FATES, let’s start with a simple model of how data and machine learning fit together. Data are fed into a machine learning algorithm to produce a model. Training data is used to build the initial model and test data is used to validate the model. In the picture below, I use “Data” to stand for both the training and test data as input to the algorithm to produce the (final) model. With such a machine model, the idea is that when new, not seen before, data come along, they are fed into the model and on this new data, the model can classify the data or make predictions.
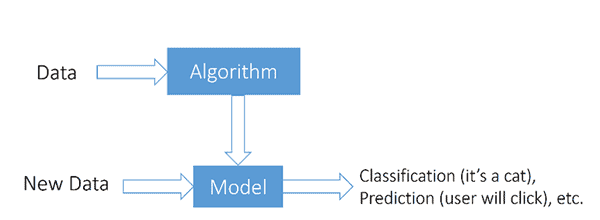
Fairness
Fairness means that the models we build are used to make unbiased decisions (e.g., classifications) or predictions.[1] Defining fairness formally is an active area of research, of interest to computer scientists, social scientists, and legal scholars (e.g., see [Barocas and Selbst 2016], [Crawford and Calo 2016], [Dwork et al. 2012], [Feldman et al. 2015], [Zemel et al. 2013]). Just one 2016 ProPublica article [Angwin et al. 2016] on machine bias caused quite a stir. The authors presented a study that shows a machine model, used by courts in the US, to predict recidivism is biased against blacks over whites. This study led academics to show the impossibility of satisfying two different, but reasonable notions of fairness simultaneously ([Chouldechova 2016], [Kleinberg, Mullainathan, and Raghavan 2017]).
Referring to the above diagram, what can go wrong? First, data is data. Data on its own is not “biased” but might come to us through some biased means. We might be collecting data unfairly, as in sampling data in a biased way. We might be choosing what aspects of observations to record (i.e., we choose which variables or features to measure). Or, data may reflect people’s biases. For example, if we have a large dataset of bank loans and the bankers who made these loan decisions are biased (e.g., racist, sexist, or otherwise discriminatory according to social norms or the law), then the dataset will reflect their biases. For simplicity, herein I use the term “biased data” to stand for all the ways that the process of data collection can be biased.
For sure (see below), if we feed biased data into the algorithm, then we are training with biased data and thus, we can expect a biased model to be produced by the algorithm. Early research is devising ways to de-bias data (e.g., [Bolukbasi et al. 2016], [Feldman et al. 2015]).
What about the algorithm itself? In principle, algorithms on their own are not biased, not any more biased than a sorting or searching algorithm; however, one could argue that an algorithm could be biased in that a human is coding the algorithm and may need to make program logic decisions that reflects that person’s bias or his/her organization’s values. Such logical decisions might need to be made where priorities must be encoded, and those orderings and weights are encoded. A more formal treatment of algorithmic bias provides another viewpoint [Friedler, Scheidegger, and Venkatasubramanian 2016].
Finally, the outcome of a model could be biased, again reflecting inherent bias present somewhere upstream from the final result.
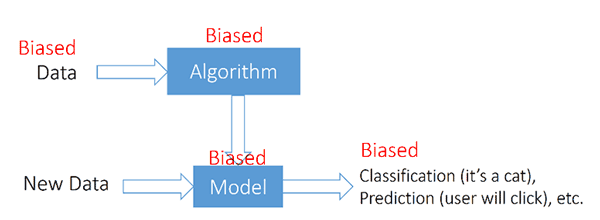
We need better clarity in pinpointing exactly what can be deemed fair or unfair: the data, the algorithm used on the training data, the model produced by the algorithm, and/or the outcome produced by the model given a new data element.
Given a definition of fairness, we then need ways to detect bias (where possible [Hardt, Price, and Srebro 2016]), and finally, ways to remediate detected bias. Ironically, using machine-learned models can reduce the bias inherent in human judgment [Corbett-Davies, Goel, and Gonzalez-Bailon 2017], but what is being reduced is the variance between humans; a biased machine-learned model will still be biased, but when used instead of humans, at least it will be used—bias and all—uniformly.
For further reading, the Columbia University Data Science Institute Fairness group maintains a list of readings on fairness and the Berkeley course on Fairness in Machine Learning has a wealth of pointers to introductory and seminal articles on fairness.
Accountability
Accountability means to determine and assign responsibility—to someone or something—for a judgment made by a machine. Assigning responsibility can be elusive because there are people, processes, and organizations as well as algorithms, models, and data behind any judgment. When AdFisher [Datta, Tschantz, and Datta 2015] discovered that on Google, ads for high-paying jobs were shown more to men than to women, it’s not at all clear whom or what to blame. From the AdFisher website, the authors ask:
Who is responsible for the discrimination results?
We can think of a few reasons why the discrimination results may have appeared:
- The advertiser’s targeting of the ad
- Google explicitly programming the system to show the ad less often to females
- Males and female consumers respond differently to ads and Google’s targeting algorithm responds to the difference (e.g., Google learned that males are more likely to click on this ad than females are)
- More competition existing for advertising to females causing the advertiser to win fewer ad slots for females
- Some third party (e.g., a hacker) manipulating the ad ecosystem
- Some other reason we haven’t thought of.
- Some combination of the above.
A new NSF Secure and Trustworthy Computing project, Accountable Information Use: Privacy and Fairness in Decision-Making Systems, aims to address accountability squarely.[2]
Transparency
Transparency means being open and clear to the end user about how an outcome, e.g., a classification, a decision, or a prediction, is made. Transparency can enable accountability.
Toward providing transparency into web services to end users, the Transparency team at Columbia University addresses questions we often ponder, such as: Am I being shown this ad because I just did a search for a similar product? The X-Ray tool correlates “Gmail ads, Amazon product recommendations, and YouTube video suggestions to user emails, wish lists, and previously watched videos, respectively” [Lécuyer et al. 2014]. (Google has since discontinued targeted ads in Gmail.) The Sunlight tool goes one step further: it determines causation of such targeting with statistical confidence, and in doing so, it uses more accurate algorithms [Lécuyer et al. 2015]. Such tools can potentially help auditors determine if a company’s privacy policies are violated. In a similar spirit, the DataMap tool built at Microsoft Research not only checks for privacy compliance on “big data” software systems, but can point to the responsible party [Sen et al. 2014]), thereby supporting some degree of accountability.
The massive amounts of data collected by third parties about our behavior means there is more information that others have about us than we have about ourselves. This lack of transparency between data collectors and data underlies the “inverse privacy” problem: the inaccessibility of data collected by others about us [Gurevich, Hudis, and Wing 2016]. We can address this imbalance by having data collectors share back their data with us. The European Union’s Global Data Protection Regulation (EU GDPR) supports this idea to some extent through its “right to access” (Article 15) and “data portability” (Article 20) mandates.
The EU GDPR’s “right to explanation” calls for transparency of data-driven automated decision-making (from Article 13, paragraph 2):
2. In addition to the information referred to in paragraph 1, the controller shall, at the time when personal data are obtained, provide the data subject with the following further information necessary to ensure fair and transparent processing: …
(f) the existence of automated decision-making, including profiling, referred to in Article 22(1) and (4) and, at least in those cases, meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing for the data subject.
“Meaningful information about the logic involved” suggests that some kind of justification is required by data collectors to provide data subjects.
Corporations are scrambling to comply with EU GDPR by May 2018 to avoid a 4% tax on their annual revenue. Meanwhile the scientific community recognizes that state-of-the-art machine learning algorithms, specifically deep neural networks (DNNs), produce scalable, practical, widely applicable, and amazing results, without a clue as to why. Understanding the fundamental principles of why DNNs work is a current research challenge. More practically, having machines provide explanations of their results that are understandable by humans is a hot topic in machine learning research today. To that end, DARPA’s Explainable AI (XAI) program supports research in both accountability and transparency of AI-based systems.
Ethics
Ethics for data science means paying attention to both the ethical and privacy-preserving use and collection of data as well as the ethical decisions that the automated systems we build will make. For the first category, the ethical issues relate to fairness, accountability, and transparency with respect to the data collected about individuals and organizations. What data needs to be collected and for what purposes are the data intended to be used? How transparent to the end user are these policies?
But it is the second category that brings ethics to the fore: Ethics is important to data science because now machines, not humans, will be programmed to make ethical decisions, some of which have no right or wrong answer. The canonical “Trolley Car Problem” raises the ethical question of whether it is better to kill one person or five. The ethical dilemma is that there is no right answer to this question. In the original formulation, a human has to decide. With the advent of AI-based systems such as self-driving cars, we can no longer ignore these unanswerable questions because the machine is going to have to make a decision: Does the car stay the course and run over the pedestrian in the crosswalk or swerve to the right and kill the people standing on the corner?
The rise of chatbots raises another ethical issue. The controversial Tay chatbot, released by Microsoft on March 23, 2016 and taken down within 24 hours, is a reminder of how difficult it is to anticipate human interactions with technology. Internet trolls found a way to make Tay say inappropriate and offensive remarks, by having her repeat what people were posting on Twitter. Here Tay offended our social norms. But, chatbots more generally spur new ethical questions: What kind of ethical responsibility do we have to remind users when they are interacting with a chatbot? If the chatbot is making recommendations on a purchase or giving medical advice, how much trust should a human put in the machine’s decisions?
Inspired by Isaac Asimov’s Three Laws of Robotics, Oren Etzioni proposes Three Laws of AI in his New York Times op-ed on How to Regulate AI, with the explicit call to start a conversation on the ethics of AI:
- An A.I. system must be subject to the full gamut of laws that apply to its human operator.
- An A.I. system must clearly disclose that it is not human.
- An A.I. system cannot retain or disclose confidential information without explicit approval from the source of that information.
Safety and Security
Safety and security (yes, two words for one “S”) means ensuring that the systems we build are safe (do no harm) and secure (guard against malicious behavior). The 2016 Workshop on Safety and Control for Artificial Intelligence, co-sponsored by the White House Office Science and Technology Policy and Carnegie Mellon University, addressed the technical challenges and known approaches to ensuring that the AI-based systems we build in the future, e.g., self-driving cars, will be safe. If we cannot ensure their safety, then consumers will not trust them. One longstanding technical challenge is to verify the safety of a digital controller interacting with a physical environment in the presence of uncertainty. One must reason about a combinatorial number of possible events and many relevant high-dimensional variables.
A new technical challenge is to verify AI systems trained on big data, e.g., a smart car’s cameras use computer vision models trained on DNNs. The recent work on Deep Xplore [Pei et al. 2017] uses techniques from software testing to test DNNs, finding thousands of flaws in 15 state-of-the-art DNNs trained on five real-world datasets. It found, for example, incorrect behaviors such as self-driving cars crashing into guardrails. This work aligns nicely with the need for accountability and transparency of machine-learning algorithms and models.
Data science raises new security vulnerabilities. Not only do we need to protect our network, our computers, our devices, and our software, but now we need to protect our data and our machine learning algorithms and models. Attackers can tamper with the data, thus producing a model that makes wrong decisions or predictions. The field of adversarial machine learning studies how malicious actors can manipulate training and test data and attack machine learning algorithms. The distinctive context here is that algorithms are working in an environment that adapts and learns from the system’s behavior to wreak havoc. Whereas for safety, our trained systems need to work in unpredictable environments, for security they work in adversarial ones.
Final Remarks
The Data Science Institute at Columbia promotes FATES in our research and education endeavors in data science. We join other organizations that have elevated the importance of similar sets of properties. The Partnership in AI spells out eight tenets that call for the technical sector, from major corporations to non-profits to professional organizations, to use AI to benefit society. Their tenets mention ethics, interpretability (transparency and accountability), privacy, and security. The FAT/ML organization lists Principles for Accountable Algorithms, calling out explainability, auditability, and fairness. More broadly, the Data and Society think tank looks at social and cultural issues arising from data-centric technology.
We should build systems with FATES in mind as we design them, not after we deploy them. By raising attention to fairness, accountability, transparency, ethics, safety, and security before data science, AI, and machine learning become commonplace, we will build systems that people can trust. Only with such trustworthy systems can data science begin to fulfill its promise to touch and transform all fields for the betterment of humanity.
Acknowledgments
I would like to thank David Blei and Daniel Hsu for their feedback and concrete suggestions, especially in sharpening some of the points on fairness.
References
- [Angwin et al. 2016] Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner, “Machine Bias,” ProPublica, May 23, 2016.
- [Barocas and Selbst 2016] Barocas, Solon and Selbst, Andrew D., Big Data’s Disparate Impact (2016). 104 California Law Review 671 (2016). Available at SSRN: https://ssrn.com/abstract=2477899
- [Bolukbasi et al. 2016] Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama and Adam Kalai, “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” NIPS, 2016.
- [Chouldechova 2016] Alexandra Chouldechova, “Fair prediction with disparate impact: A study of bias in recidivism prediction instruments,” FATML 2016.
- [Corbett-Davies, Goel, and Gonzalez-Bailon 2017] Sam Corbett-Davies, Sharad Goel, and Sandra Gonzalez-Bailon, “Even Imperfect Algorithms Can Improve the Criminal Justice System,” op-ed, New York Times, December 20, 2017.
- [Crawford and Calo 2016] Kate Crawford and Ryan Calo, “There is a blind side in AI research,” Nature, vol. 538, no. 7625, October 2016.
- [Datta, Tschantz, and Datta 2015] Amit Datta, Michael Tschantz, and Anupam Datta, “Automated Experiments on Ad Privacy Settings: A Tale of Opacity, Choice, and Discrimination,” Privacy Enhancing Technologies, 2015.
- [Dwork et al. 2012] Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, Rich Zemel, “Fairness Through Awareness,” Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, January 2012
- [Feldman et al. 2015] Michael Feldman, Sorelle A. Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian, “Certifying and Removing Disparate Impact,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’15). ACM, New York, NY, USA, 259-268. DOI: https://doi.org/10.1145/2783258.2783311
- [Friedler, Scheidegger, and Venkatsubramanian 2016] Sorelle A. Friedler, Carlos Scheidegger, Suresh Venkatasubramanian, “On the (im)possibility of fairness,” https://arxiv.org/pdf/1609.07236.pdf, Sept. 2016.
- [Gurevich, Hudis, and Wing 2016] Yuri Gurevich, Efim Hudis, and Jeannette M. Wing, “Inverse Privacy,” Communications of the ACM, Vol. 59, No. 7, July 2016, pp. 38-42.
- [Hardt, Price, and Srebro 2016] Moritz Hardt, Eric Price, and Nathan Srebro, “Equality of Opportunity in Supervised Learning,” NIPS 2016.
- [Kleinberg, Mullainathan, and Raghavan 2017] Jon Kleinberg, Sendhil Mullainathan, Manish Raghavan, “Inherent Trade-Offs in the Fair Determination of Risk Scores,,” to appear in Proceedings of Innovations in Theoretical Computer Science (ITCS), 2017.
- [Lécuyer et al. 2014] Mathias Lécuyer, Guillaume Ducoffe, Francis Lan, Andrei Papancea, Theofilos Petsios, Riley Spahn, Augustin Chaintreau, and Roxana Geambasu, “XRay: Enhancing the Web’s Transparency with Differential Correlation,” USENEX Security, 2014.
- [Lécuyer et al. 2015] Mathias Lécuyer, Riley Spahn, Yannis Spiliopoulos, Augustin Chaintreau, Roxana Geambasu, and Daniel Hsu, “Sunlight: Fine-grained Targeting Detection at Scale with Statistical Confidence,” ACM CCS 2015.
- [Pei et al. 2017] Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana, “Deep Xplore: Automated Whitebox Testing of Deep Learning Systems, Proceedings of the 26thACM Symposium on Operating Systems Principles, October 2017, Best Paper Award.
- [Sen et al. 2014] Shayak Sen, Saikat Guha, Anupam Datta, Sriram K. Rajamani, Janice Tsai and Jeannette M. Wing, “Bootstrapping Privacy Compliance in Big Data Systems,” IEEE Symposium on Security and Privacy (“Oakland”), May 2014.
- [Zemel et al. 2013] Richard Zemel, Yu (Ledell) Wu, Kevin Swersky, Toniann Pitassi, and Cynthia Dwork, “Learning Fair Representations,” Proceedings of the 30th International Conference on Machine Learning, 2013.
[1] Here, I use the term “bias” as a social or ethical concept, in contrast to the technical meaning used in statistics. Unfortunately, there is ambiguity with this term as well as the term “fairness.”
[2] In the interests of full disclosure, I am on this project’s advisory board.
Jeannette M. Wing is Avanessians Director of the Data Science Institute and professor of computer science at Columbia University.